Data Integrity
Like any modern file system, the Tintri file system employs various techniques to maintain the end-to-end integrity of the data stored within. There are numerous causes of data integrity loss:
- Storage media degradation
- Reading/writing to incorrect locations on the media
- Memory corruptions
- Errors during data transfer over interconnects
- Software bugs
A set of basic error checks are employed within hardware that try to protect data at the individual component level. The storage media itself has the ability to indicate if a particular data block was corrupted due to device degradation. In addition, communication protocols like PCIe or SCSI takes care of the checksumming of the data at endpoints to protect against bit flips. Also, the system memory has its own error checking and correction codes to ensure that its integrity is maintained.
Integrity of data is checked at various stages throughout the Tintri file system:
- Data and metadata pages during access
- Data segments are scrubbed periodically for object validity
- RAID stripes are validated periodically
- NVRAM data is validated before replayed to disk
- File and snapshot checksums are validated prior to deletion
Overall, the Tintri file system was designed with an exhaustive set of mechanisms to ensure complete end-to-end data integrity for the entire storage system. These include things like:
- Internal checksum or hashes for self-validation of objects
- Compressed blocks written to media (e.g., flash and hard disks)
- Compressed metadata pages written to flash
- RAID objects that contain multiple compressed metadata blocks and data pages
- NVRAM data blocks
- Mirrored state to standby controllers
- External checksums or hashes for objects stored within references
- Block or extent metadata containing pointers to compressed data blocks
- Transactional updates for files or snapshots that store cumulative hashes
- Clones and snapshots inherit content, checksums, and hashes from parent objects
An individual data block may be unreadable if bits are flipped on the storage medium or if there are firmware errors. Drives generally suffer from many types of failures, such as silently losing a write, writing a block to an incorrect location, or reading data from an incorrect location. File systems must be able to detect and correct errors. Tintri OS’s RAID 6 software detects and self-heals errors in real-time.
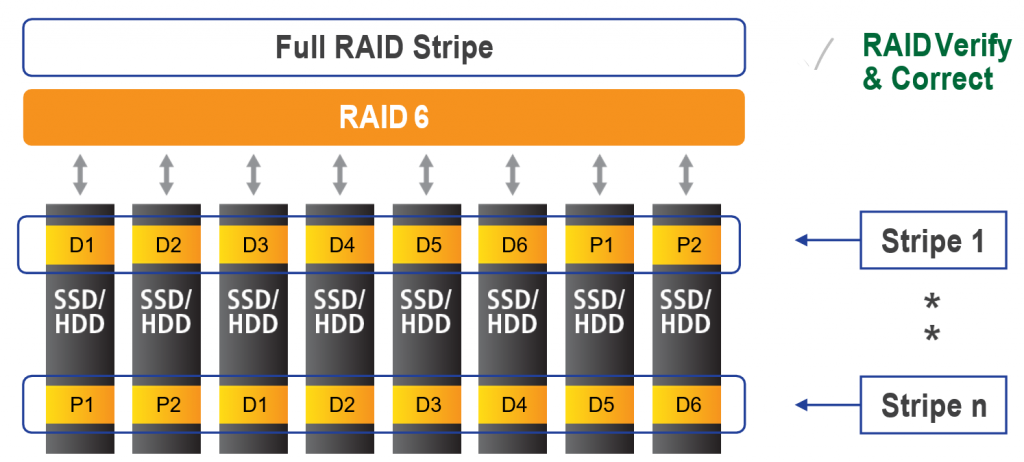
Figure 2. Tintri’s RAID 6 configuration.
The underlying file system of the Tintri OS stores all of the objects it manages — metadata and data — in blocks with strong checksums. On every read, the file system first verifies the object read from disk by computing checksums and ensuring the computed value matches what is retrieved. If an issue is found, RAID 6 corrects and self-heals the system. See Figure 2 for more information.
When Tintri OS receives a write request, after analyzing for redundancy, it stores the data block along with its checksum on SSD. For a duplicate block, a read is issued for the existing block from flash to ensure a match. A checksum is computed and stored with each data object — both in flash and on disk— and verified whenever the object is read. A self-contained checksum may be valid if a drive substitutes one read for another because of DMA errors, internal metadata corruption, etc. This means an inline checksum by itself cannot catch all device errors.
A referential integrity check is needed to detect corruption, to avoid bigger issues by returning incorrect data. To ensure referential integrity, references to data objects contain a separate checksum that is verified against the checksum of the object being read.
These techniques ensure the data on SSD and HDD are readable and correct, and the file system metadata used to locate data is readable and correct. Potential problems, such as a disk controller returning bad data, are caught and fixed on the fly.
Logical File Contents, Verified on Deletions and in Replication
RAID-assisted real-time error detection works well for active data, but does not address errors with cold data, such as data blocks referenced by snapshots for long periods of time. To guard against corruption, VMstore appliances actively re-verify data integrity on SSD and HDD in an ongoing background process.
For data stored on HDD, there are two levels of scrub process to identify and repairs errors:
- As new data and its checksums are written, a background process reads entire RAID stripes of data written to disk and verifies checksums for If there is an error, RAID heals the system in real time. This helps correct transient errors that may occur in the write data path.
- A weekly scheduled scrub process that requires no user intervention re-verifies all data stored on disk, ensuring any errors are detected and This helps correct cold-data errors.
For data stored on SSD, a continuous scrub process runs in the background to read full RAID stripes of data at fixed-time intervals, and compares computed checksums. If there is an error, RAID corrects errors in real time. Checksums for each data object inside the RAID stripe are also computed independently and matched with what is retrieved from SSD.
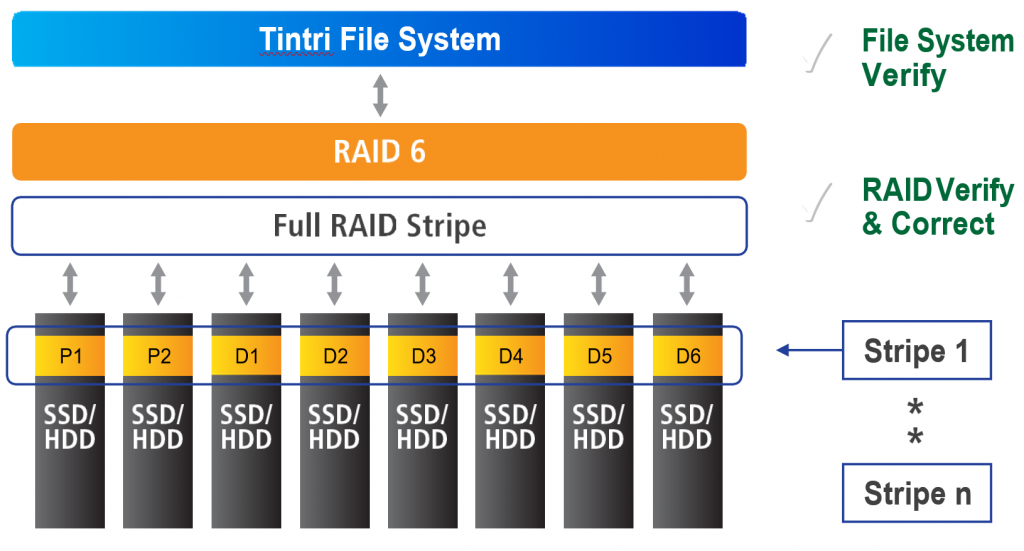
Figure 3. Tintri RAID 6 error correction.
Through RAID 6 real-time error correction and ongoing scheduled data scrubbing, most storage-medium generated errors are identified and fixed with no impact to file system or storage system operation. The process is shown in Figure 3.
Tintri’s file system stores data on SSD (in blocks) and on HDD (in extents). The metadata that describes the data is stored on SSD (in pages organized in page pools). Every object – data block or extent and metadata page – has a checksum and a descriptor (the self-describing module of an object). The descriptor of a data object describes the file and the offset in that file the object belongs to; and similarly, the descriptor of a metadata page describes the page pool to which a metadata object belongs and whether it is the latest version.
Tintri file system stores checksums that tie an object and its descriptor, so that lost writes, misplaced reads, or other such perfidious errors do not corrupt data (Figure 4). The self- describing nature of data and metadata helps recover from disk and firmware errors.
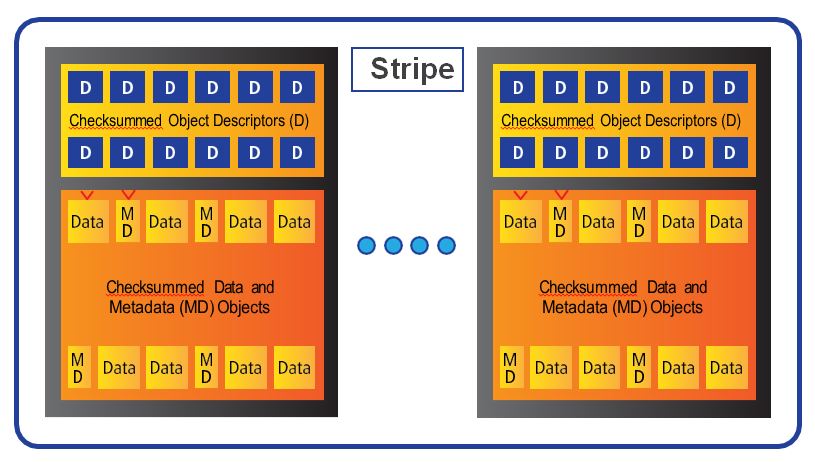
Figure 4. Tintri file system checksum overview.
The Tintri file system consists of a hierarchy of references with blocks and extents at the lowest level and metadata mapping them at higher levels. Referential integrity is maintained at each level using strong checksums to detect errors. The checksums defend against aliasing issues such as a file pointing to wrong data blocks. Further, metadata objects have a version number in metadata pages to detect similar aliasing issues.
Data blocks and extents are written to SSD and HDD, respectively, in full RAID stripe units. Techniques described in self-healing file system detect and correct errors with cold data. In the unlikely event that an unrecoverable disk error causes orphaned or corrupt objects, a scan of the self-describing objects helps detect and correct the problems.