Disk-Based Health Check
On the primary node, one of the HAMon’s threads (“heart beat”) periodically refreshes the reservation key for all 8 SSDs, and the standby checks for the reservation holder status. When the HAMon on standby detects that the primary is not responding to the network-based health check, then it starts monitoring the key status for some number of times [haMonPeerAcquiredPollCount (4)] with intermittent delays [haMonPeerAcquiredPollIntervalUs (0.5s)] inserted. If the key doesn’t get changed even at the end of this duration (4 * 0.5 = 2 secs), then it’s going to shoot primary node, reset and acquire reservations.
Right now the refresh interval rate of once every 0.5 secs is very aggressive, as the operation to change the key for all 8 SSDs itself takes ~2.4-3.1 secs. Due to this very aggressive refresh interval, IO performance drops significantly (Bug 7226). There are a couple of approaches to tackle this issue.
- Tweak the refresh interval rate to higher value. Performance experiments have been run with various interval rates from 1s to 7s, and it showed that any value <8-10secs is not going to help. Setting a value >= 8-10secs will result into stretched failover detection time by the same amount, and hence is probably not a good solution.
- Dynamically arm and disarm the SSD reservation key refresh. With this approach, the “heartbeat” thread on the primary node will keep track of the pings coming from the secondary node, and if they have not been received for some amount of time [haMonPeerAcquiredPollIntervalUs (0.5s) * 6 = 3s], then it’s going to trigger the key refresh, an indication that it’s alive to the secondary node. If we are continuously not receiving pings, then the refresh window will be pushed further. And the refresh will be terminated when the refresh window expires, which is right now defined as 4 secs [2 * haMonPeerAcquiredPollIntervalUs (0.5s) * haMonPeerAcquiredPollCount (4)]. If we continue to be in the state where pings are not received even after the extended period of time [haMonPeerAcquiredPollIntervalUs (15m)], then we slow down on the refresh rate on the primary and fence check rate on the standby node. The purpose of the “slow refresh rate” is there is no point in refreshing when a controller is yanked out or down for too long (waiting for a service call, etc). Note if a ping is not received but a subsequent one arrives, the refresh won’t be stopped immediately (instead, the window will expire). This is to handle the race conditions between what standby and primary HAMons think about each other’s state.
- HAMon on the primary node updates all SSDs (or quorum disks) with a monotonically increasing sequence number at a pre-defined LBA, and the HAMon on the secondary node checks for the change in that value. If it doesn’t get changed within the specified interval, then standby can send primary, reset and acquire Reservations.
Since approach 1 bloats the failover time, and approach 3 requires quite a few changes, approach 2 will be the main solution unless any design/implementation gaps are encountered. Note that the mechanism to fence the disks still stays the same.
Each HAMon is responsible for assessing the state of its own node. The state values track the status of a node as shown in Figure 82.
enum NodeRole {
nodeRolePrimary = 1, // Node servicing operations.
nodeRoleSecondary = 2, // Node tracking operations in standbye.
nodeRoleUnavailable = 3, // Node is unavailable.
};
enum NodeStatus {
// Primary Status Values
nodeStatusSelected = 1, // Node selected as primary.
nodeStatusRecovering = 2, // Node recovering as primary.
nodeStatusActive = 3, // Node active as primary.
// Secondary Status Values
nodeStatusConnecting = 4, // Secondary connecting to Primary.
nodeStatusSyncing = 5, // Secondary syncing from Primary.
nodeStatusSynced = 6, // Secondary in sync with Primary.
nodeStatusDisconnected = 7, // Secondary lost connection to Primary.
// Unavailable Status Values
nodeStatusNone = 8, // No status for unavailable node.
nodeStatusUpgradePending = 9, // Indicate an upgrade is pending.
nodeStatusUpgrading = 10, // On-disk format upgrade in progress.
nodeStatusFenced = 11, // Disks are fenced on the node. This
// status is set by tools.
};
typedef uint32 NodeErrors;
static const uint32 nodeErrorOutOfSync = 0x0001; // Node is out-of-sync with on-disk state.
static const uint32 nodeErrorNodeDown = 0x0002; // Node is down (powered off, rebooting, dead, or can't communicate)
static const uint32 nodeErrorInactive = 0x0004; // Filesystem process is not running
static const uint32 nodeErrorNoDataNetwork = 0x0008; // No data network connectivity.
static const uint32 nodeErrorIncompatible = 0x0010; // Node is incompatible with on-disk data (software version, hardware)
static const uint32 nodeErrorConfigSync = 0x0020; // Configuration needs to be synced from the Primary.
static const uint32 nodeErrorNoAdminNetwork = 0x0040; // No admin network connectivity.
Figure 82. Tracking the node state.
The node-specific state also includes the file system process mode and status values queried from ProcMon, and file system version/release information. HAMon queries the VMstore process via thrift for the file system process view of role, status, and errors set. HAMon periodically polls VMstore for its NodeRole, NodeStatus, and NodeError values. When VMstore updates these values, it doesn’t have to explicitly contact HAMon to push the updates.
The default behavior for setting a NodeErrors is to cause the role to be set to UNAVAILABLE, but certain errors have special handling, described below. Most errors result in the NodeStatus being set to NONE.
The FENCING NodeStatus values behaves like locks. If the file system is UNAVAILABLE with NodeStatus NONE, setting NodeStatus to FENCED causes the disks to be fenced.
If disk fencing fails, the request to change to FENCED NodeStatus results in errHAMonFenceFailure being returned from the status change request. Requesting a transition from FENCED NodeStatus to NONE causes the disk fencing to be disabled. The FENCED status is typically set by tools that need read/write access to shared data. The tool tries to set FENCED status. If it fails, the tool exits with an error. If it succeeds, it has access to shared storage, and on exit it sets the status to NONE.
UPGRADEPENDING and UPGRADING status values are set during upgrade. They may only be validly set when the status is NONE. These status values do not result in fencing the disks, and are used by system upgrade to communicate the upgrade status to the peer node.
The nodeErrorOutOfSync error is set for Secondaries with NodeStatus SYNCING. VMstore also contacts HAMon to set this error when VMstore is promoted to primary and discovers that its NVRAM generation number does not match the generation number on disk. The nodeErrorOutOfSync error prevents a secondary from being promoted to primary until the NodeStatus has changed to SYNCED. This error does not cause the role to be set to UNAVAILABLE.
The nodeErrorNodeDown error is set when the cross-node network connection is unavailable and node status queries to the peer node fail. HAMon crafts node state for the out of contact node using disk fencing and current node information to determine whether the other node is a functioning primary or unavailable. This error to indicate the state for the node has been inferred.
If the file system process is in ENABLED mode with RUNNING status, the file system process is considered active. Otherwise, the nodeErrorInactive error is set and the process becomes UNAVAILABLE.
If a node’s client data network links lose carrier, the nodeErrorNoDataNetwork error is set. This error is specially handled. A timestamp is noted when the client network link is lost and the error is ignored until a configured amount of time has passed. This avoids having transient network link losses cause failovers. The error will trigger a failover when the primary is active and the secondary is synced and has client data network connectivity. The error does not preclude a node from being selected as the primary, because the one node with NVRAM contents that match the on-disk state may have not have client data network links. Allowing the node to become primary allows a secondary to synchronize with the primary and take over.
Similarly, if a node’s admin network link loses carrier, the nodeErrorNoAdminNetwork error is set. Failover is performed if the secondary is synced and has both data and admin connectivity.
The error nodeErrorIncompatible is set when the node software is incompatible with the on-disk format.
Figure 83 shows the main NodeState transitions.

Figure 83. Node state transitions.
Note 1: The VMstore process on startup assumes the role of a secondary. During bootup, both nodes come up as a secondary. A secondary VMstore attempts to connect to the peer node primary VMstore to synchronize its state. If the peer node is a secondary, it doesn’t listen on the primary port and refuses connection attempts from a peer secondary.
Note 2: In order to maintain clarity, this diagram does not show the special handling for the nodeErrorNoDataNetwork, nodeErrorNoAdminNetwork, and nodeErrorIncompatible errors.
Each HAMon assesses its own state on a periodic basis. When a cluster status query is received, HAMon queries the peer node for its current state and calculates the PairState value as a summation of the overall cluster status.
The state values that track the state of the node pair are shown in Figure 84.
enum PairState {
pairStateInvalid = -1, // Invalid pair state
pairStateOffline = 1, // Both nodes are unavailable.
pairStateStartup = 2, // First Primary is selected.
pairStateOperational = 3, // Secondary unavailable in the event the Primary fails.
pairStateRedundant = 4, // Secondary can takeover from Primary.
pairStateFailover = 5, // Secondary is in the process of taking over for failed Primary.
};
typedef uint32 PairErrors;
static const uint32 pairErrorLinkDown = 0x0001; // The cross-node network link is down
Figure 84. State values that track the node pair.
Figure 85 shows the PairState transitions.
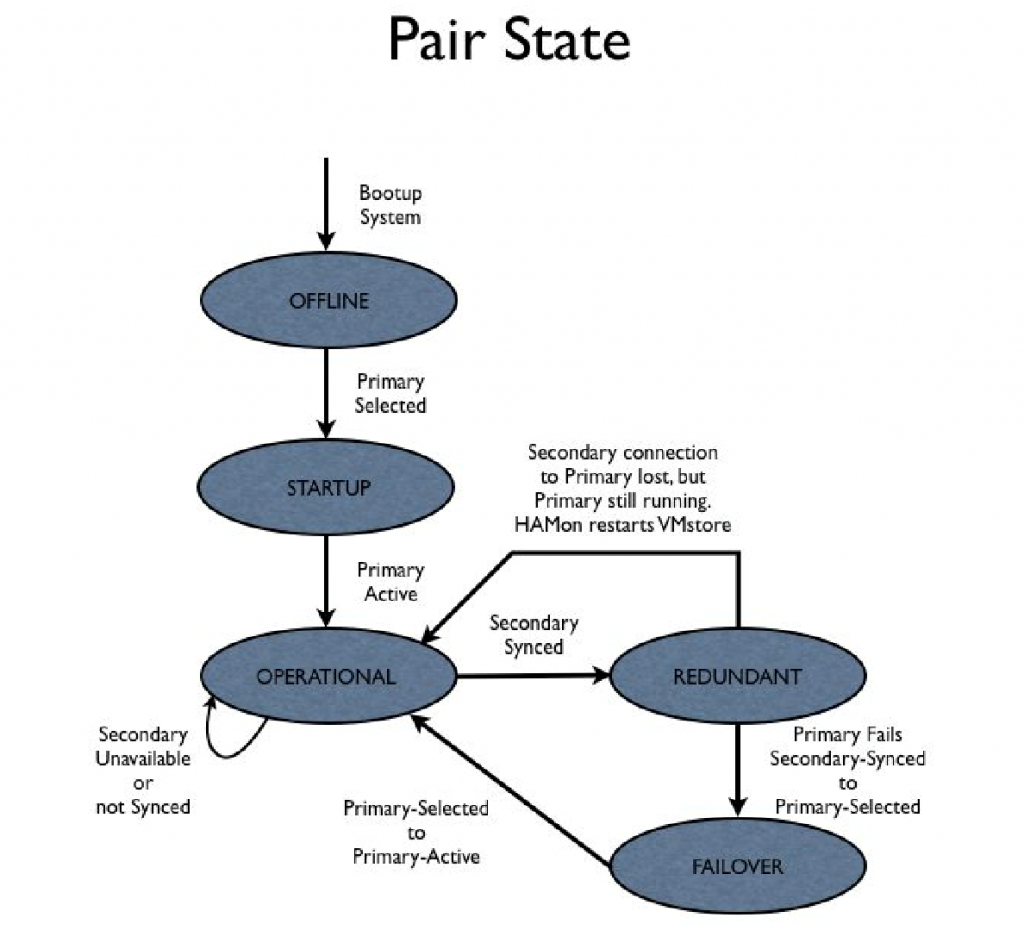
Figure 85. PairState transitions.
If the link between the nodes is down, HAMon infers the state of the peer node based on disk fencing. The PairState value is used for reporting/diagnostic purposes only; it does not drive state transitions.
Figure 86 shows how cluster status queries are serviced.
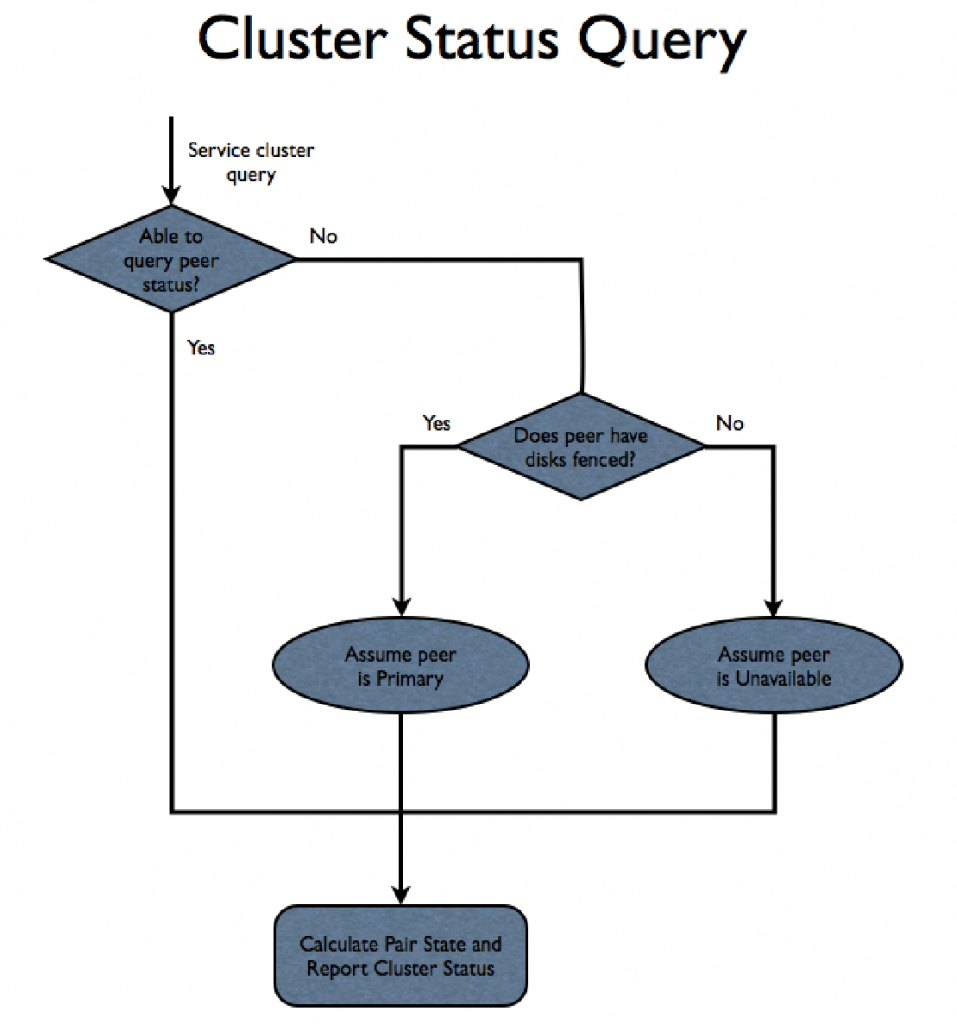
Figure 86. How a cluster status query is handled.
Mirroring
A node is eligible to be a primary only if it has the most current NVRAM contents. If this is violated, the file system can lose data that was written by NFS clients and acknowledged. This is a form of silent corruption that must be prevented. This problem is addressed by introducing the concept of a generation number that matches the NVRAM contents to disk.
The following state must be stored in NVRAM and on-disk:
NVRAM
- UUID instance id set at file system format
- Generation number
On-Disk
- UUID instance id set at file system format
- Clean shutdown boolean
- Current generation number
- Intended generation number
The UUID is used to validate NVRAM contents match the on-disk file system instance. This prevents stale NVRAM data from being used if the file system is reformatted or an NVRAM card with old contents from another node is installed.
The clean shutdown boolean is set on-disk when the file system is cleanly shut down. During clean shutdown, the NVRAM contents may be zeroed. The clean shutdown boolean is an indication that a node with zeroed NVRAM can be eligible to be the primary.
The NVRAM state is readable on a node at all times, but the on-disk state may only be read after assembling the RAID. VMstore, when informed it has been selected as the primary, will assemble the RAID. The NVRAM and on-disk state may then be compared to the local NVRAM’s generation number.
The on-disk state has two copies of the generation number:
- The current generation number
- The intended change to the generation number
On format, the generation numbers in each node’s NVRAM and both generation numbers on disk (current and intended) are set to 1.
The NVRAM and on-disk generation numbers are considered to be a match if the NVRAM generation number is greater than or equal to the current generation number on disk.
All VMstores start out as a secondary, and eventually transition to being the primary. The transition to primary involves first checking that the NVRAM contents match the disk. This is confirmed if the NVRAM generation number is greater than or equal to the current generation number on disk.
If the on-disk Clean shutdown boolean is true, the generation number and NVRAM contents don’t matter, are reinitialized, and treated as a match. Once the NVRAM contents are a confirmed match, the generation number is incremented as follows:
- Read the intended generation number on disk and increment it +1
- Set the NVRAM generation number to match the intended generation number on disk.
- Set the current generation number on-disk to match the intended generation number.
- Clear the clean shutdown boolean.
The following crash scenarios illustrate how the generation number is updated:
- Format the file system and all generation numbers are initialized to 1.
- Node0 is selected to be the Primary [NVRAM0 1, NVRAM1 1, current 1, intended 1]
- The on-disk intended generation number is incremented. [NVRAM0 1, NVRAM1 1, current 1, intended 2]
- Node0 primary crashes
- Node1 comes up as a primary
- The generation number matches (NVRAM1 1 vs current 1)
- Bump the intended generation number. [NVRAM0 1, NVRAM1 1, current 1, intended 3]
- Set the NVRAM generation number [NVRAM0 1, NVRAM1 3, current 1, intended 3]
- Node1 Primary crashes
- Node0 is selected to be the primary
- The generation number matches (NVRAM0 1 vs current 1)
- Bump the intended generation number. [NVRAM0 1, NVRAM1 3, current 1, intended 4]
- Set the NVRAM generation number. [NVRAM0 4, NVRAM1 3, current 1, intended 4]
- Set the on-disk current generation number. [NVRAM0 4, NVRAM 3, current 4, intended 4]
- Node0 primary accepts data that Node1 NVRAM will not have
- Node0 primary crashes
- Node1 is selected to be the primary
- The generation number does not match (NVRAM1 3 vs. current 4)
- Node1 is correctly prevented from coming up as the primary
- Node0 comes back and becomes primary again
- Node0 is cleanly shut down and the on-disk Clean boolean is set
- Node1 is rebooted and is selected as primary
- Node1 is allowed to become primary with stale NVRAM contents because the on-disk state is marked Clean
A primary must update the generation number prior to accepting changes to the NVRAM state. The generation number must be updated prior to NVRAM recovery, unless there is some way to communicate recovery state between the nodes. The reasons for this:
For recovery of metadata operations, the firstUnstableStasisLsnAfterCrash field stored in the flog partition of NVRAM is relied on to correctly handle crashes during recovery. During the recovery process, this field in NVRAM is updated. (See Nvram Recovery Spec For Metadata Ops for more details). If one controller starts recovery and updates this field, then subsequent re-tries of recovery must use this information to filter out log entries to recover. If the other controller is allowed to perform recovery after the first controller has started recovery, the other controller would not have the updated firstUnstableStasisLsnAfterCrash field stored in its Nvram, resulting in incorrect recovery.
It is also essential that the generation number be updated prior to the Flog incarnation number update performed on Flog initialization. Updating the generation number just after a match is determined, and before further system startup, should satisfy both requirements.
The primary must also update the generation number when it fails to mirror an operation to the secondary because of a loss of synchronization protocol connection. This is essential because the failure to mirror is the first instance where the primary is accepting client data that will not exist in the secondary’s NVRAM, and the secondary must be made ineligible to become the primary without a re-sync.
A secondary updates its NVRAM generation number as a function of NVRAM syncing. A secondary syncs the NVRAM contents from the primary and updates the generation number at the end of the syncing process. The generation number update indicates that the secondary is now qualified to become the primary.
An otherwise functional primary node where the client data network links are down cannot be considered available. HAMon will monitor the network carrier on the client data network links.
A loss of carrier will occur if the network link is unplugged or if the attached switch is down. The network carrier does not provide a guarantee that network routing is functional, but will be considered sufficient to monitor in the initial product. It is assumed that an installation concerned with network availability would have two independent switches in which each of the two client network links on a node are connected to a different switch. This way the failure of a single switch will not disrupt the client network.
The platform library can either provide an interface that can be used to poll for the network condition, or an interface that monitors kernel network change notifications.
If all links on the primary are lost, failover is performed if there is a synchronized Secondary with an active data link. A timeout hysteresis will be applied to the link loss to avoid having transient link losses cause spurious failovers. Loss of client data links does not prevent a node from being selected as primary, because the one node with NVRAM contents that match the on-disk state may have no client data network links. Allowing the node to become primary allows a secondary to synchronize with the primary and subsequently failover. Note that this assumes NVRAM sync is proactive and not driven by incoming client data.
Each node also has a separate administration network link. If the secondary is synced and has functioning data and admin links, the system will fail over. Data link connectivity will take precedence over admin network connectivity when determining which node should be primary.
The client network links on the two nodes are configured for failover. HAMon is responsible for invoking a script to perform IP address takeover for the client links. This directs client network activity to the newly-instantiated primary. See “System Management Failover” for more details.
The two nodes in the HA cluster are cross-connected via dual 10gE direct network connections. Loss of cross-node connectivity is rendered safe by arbitrated using disk reservations.
Disk Fencing
The idea behind disk fencing is to guarantee that only one node has write access to shared storage. Fencing also ties in with the concept of “heartbeating:” the communication between nodes used to determine when a failure has occurred.
Disk fencing can be accomplished using special SCSI reservation commands. A node that holds a SCSI reservation on a drive is guaranteed that requests from other nodes will be rejected at the drive. SCSI reservations come in two flavors: SCSI-2 and SCSI-3. SCSI-2 reservations are not persistent across SCSI resets, while SCSI-3 supports persistent reservations and a richer set of sharing semantics.
Flash drives do not natively support SCSI reservations. An interposer is used to adapt flash drives to SAS. The straightforward way to fence disks using SCSI reservations is to have nodes competing for the reservation issue a reset to break any existing reservations. The node then waits to see if reservations are renewed. If the reservation fails to be renewed within a specified timeout, the peer node acquires the reservation.
In this disk fencing approach the reservation renewal acts as a “heartbeat,” indicating node liveness. The downside of this approach is the timeout required, which is estimated to be somewhere in the 3-5 second range, based on observed 1.6s write latency spikes. HA failover is operating under a tight time budget, and the reservation timeout can cause failover detection to consume a significant portion of that budget.
The spinning disks pose a challenge because the shared partitions need to be fenced, while other partitions are dedicated for local node use. There is no SCSI support for reserving portions of a drive. The simplest approach is to power cycle the peer node when the flash SCSI reservations have been successfully acquired. The downside of power cycling is it will prevent a coredump from being written in the case of a failover caused by a crashing primary VMstore.
An alternative approach to protecting spinning disks is to somehow have a way to turn off new IOs and wait for completion of any in-flight IOs. This will take the form of kernel driver support. The driver will provide ioctls for turning on/off IOs to the device, and an ioctl to query the current setting. A primary node HAMon detecting that the VMstore is crashing can turn off the IOs, allowing the peer node to take over as primary without the danger of conflicting IOs. While IOs are disabled, a VMstore coredump may continue to be written to a non-shared partition on the drives.
Figure 87 shows the fencing algorithm.
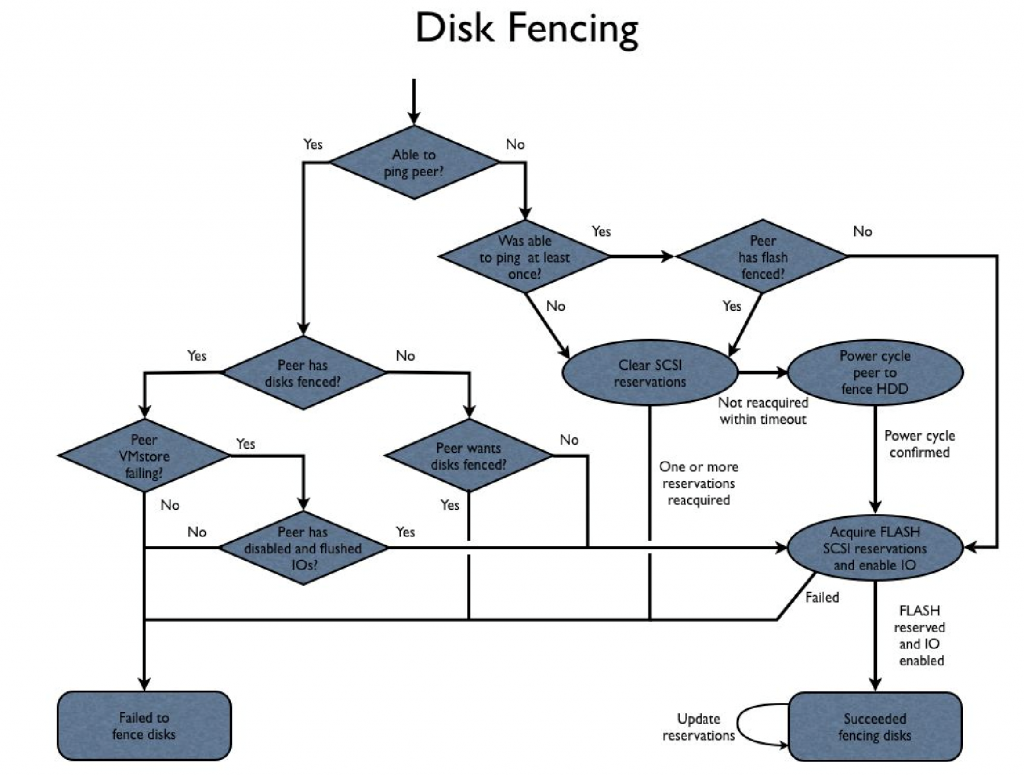
Figure 87. Disk fencing.
During cluster bootup, the nodes will tend to start at the same time and could both try to fence the disks at the same time. The fencing algorithm needs to avoid getting into a situation where both nodes want the fence, synchronize, and continuously prevent each other from acquiring the fence. This could happen if both nodes detect their peer wants the fence and backs off, or if both nodes were to shoot each other. This is avoided by having Node1 back off and delay if it detects that Node0 is trying to acquire the fence.
Failovers can be classified into two categories: controlled and uncontrolled. A controlled failover is a case where a failover is intentionally triggered. In this case, it is possible to do clean shutdown and notify the secondary node of the intention to fail over, rather than require the secondary to detect the “failure”.
An uncontrolled failover occurs when the secondary does not get advance notice of the failure and must detect the failure has occurred. The main customer test scenario is an uncontrolled failover caused by powering off a node and timing the failover.
The HA design must optimize for this case. Another form of uncontrolled failure occurs when the VMstore process dies. In this case, the process failure must be detected on the failing node and, since the node is otherwise alive, the secondary may be notified of the failure rather than waiting to detect the failure.
In the uncontrolled case where the primary node does not respond to a ping, failure detection can occur in the second range. The rest of the fencing cost is the time needed to power cycle and get an acknowledgement that the power cycle has occurred.
The rest of the time is spent resetting any reservations currently held by the power cycled node and acquiring the reservations. Detection plus fencing should cost something in the range of 2-3 seconds. This failure scenario is expected to be the main scenario tested by customers when assessing the product’s failover capabilities.
Note that experience with the current interposer shows that acquiring reservations and releasing reservations can take as much as 4s and 2s respectively, extending the expected failover time. This can considerably extend failover times. In the uncontrolled case where the primary VMstore process is failing, detection is more expensive.
The time ProcMon takes to discover that the primary process is failing adds additional time. ProcMon currently polls for process status every 5 seconds. This polling interval will need to be tightened considerably. Process failure detection could potentially be brought down to something like 1 second. The secondary node cannot fence the disks until the failing primary has shut off new IOs and flushed in-flight IOs. This may need another second. After the sub-second detection time on the secondary (potentially assisted by a hint sent from the failing node), the secondary must acquire all the disk reservations. The current guess for this scenario is somewhere in the range of 3.5 seconds.
This failure scenario is the one that occurs when the VMstore process crashes unexpectedly. Note that a hung VMstore is currently detected by Queue Monitor, and a crash is induced after 5 minutes. Thus, without considerable tuning, the quoted time is +5 minutes for hang conditions.
The controlled case VMstore incurs much of the cost of the uncontrolled failing process case. The 1 second of process failure detection is saved for a total near 2.5 seconds. This does not allow for a clean shutdown of the file system where the current shutdown scripts allow as much as 330 seconds for this to complete.
Disk fencing updates and monitoring are time sensitive, and become increasingly so as the tolerances on failure detection are tightened. The threads responsible for these operations may benefit from setting FIFO scheduling. HAMon will pin itself in memory to avoid time delays caused by swapping.
The node power cycle is performed using the IPMI interface. The power cycle request must not only return when the request is successfully accepted, but must return with a guaranteed completion. It is critical that the power cycle request be reliable, otherwise corruption can occur.
As an added safeguard, the nodes can perform a periodic IPMI health check. If IPMI is having problems on the local node, the node can power cycle itself. That way the node acquiring the disk fence may have trouble power cycling the peer node, but the peer node will not be a bottleneck. The power cycle may clear up IPMI issues and allow the live node to detect the power cycle, allowing it to continue to fence the disks and failover.
When a node’s HAMon successfully fences the disks, the node becomes responsible for servicing system management requests. If neither node has the disks fenced, but are both up, Node0 is responsible for servicing system management. If a node is unable to contact its peer (either the node or crossnode communication are down) and the peer doesn’t have the disks fenced, an ARP ping to the system management IP address is used to determine whether the peer node is servicing system management.
Failover/Recovery Time
When responsibility for system management is assumed by a node, the ‘takeover.sh’ script is executed with “start” specified on the command line. This script is responsible for taking over the client network IP addresses and setting up system management on the node. This script will periodically be called and must be idempotent. When the management responsibility is moved to the peer node, the ‘takeover.sh’ script is executed, with “stop” specified on the command line.
Figure 88 shows the flow for the system management failover thread.
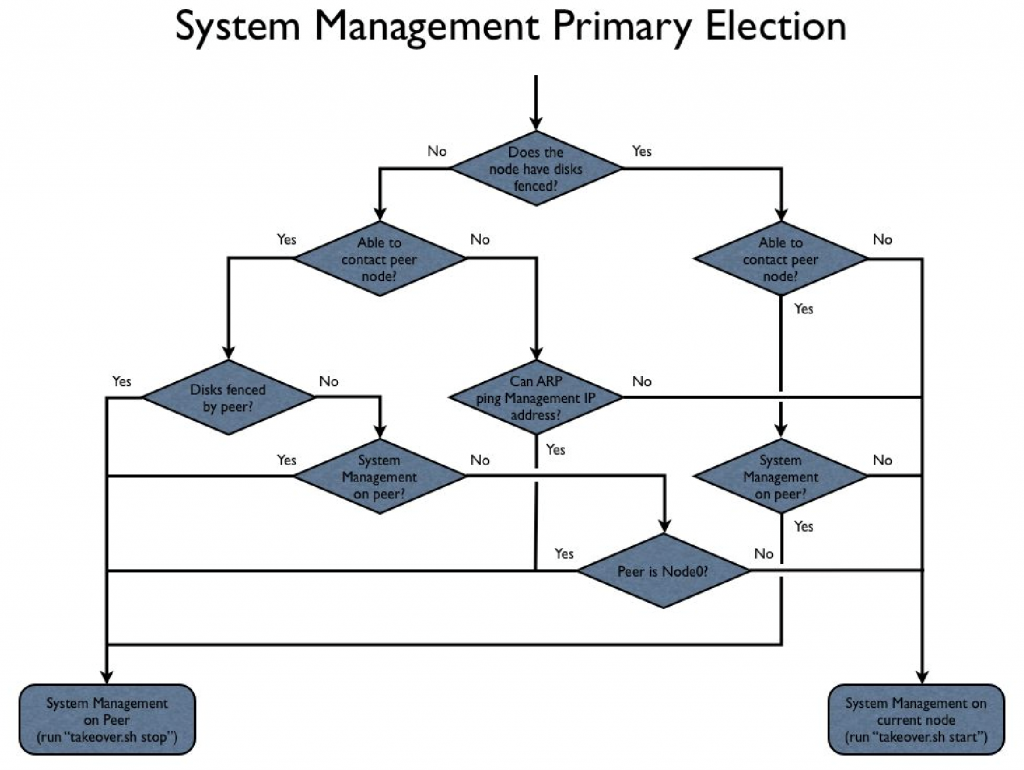
Figure 88. How system management failover happens.
NOTE: System Management Primary Election could potentially take into account network link on the management IP interface. Doing so would result in scenarios where management is not serviced from the file system primary node. Currently, the plan is to have the ‘takeover.sh’ script takeover both system management and the client network IP addresses; these responsibilities would have to be split between separate file system and management takeover scripts.
The Apache Tomcat server is responsible for servicing system management requests. Both nodes run a copy of Tomcat and a local copy of the database. Initially, Tomcat comes up on both nodes as a secondary (i.e., running, but not accepting/processing system management requests).
The script “takeover.sh start” discussed earlier invokes a command that communicates with the local Tomcat server and tells it to become the primary. Should Tomcat die, it will come up as a secondary and “takeover.sh start” will periodically be invoked to re-nominate Tomcat as primary.
The Tomcat server remains the primary Tomcat until a decision is made to move management, at which time “takeover.sh stop” is invoked. The “stop” clause should gracefully contact and allow Tomcat to decide whether it needs to restart to revert to secondary. The “stop” clause must be idempotent.
The secondary Tomcat needs to sync the database from the primary. HAMon will call the ‘sync.sh’ script when VMstore tells HAMon to change the NodeStatus to SYNCING. The ‘sync.sh’ script will call a command that tells Tomcat to sync from the primary. The command will return without waiting for the sync to complete. The presumption is that database sync will complete before the secondary is called upon to become the primary, but an unsynced database doesn’t preclude becoming the primary.