HAMon
Each node runs an instance of the HAMon daemon. Each HAMon independently assesses the state of its own node. The HAMons also communicate to exchange peer node state and manage the election of a Primary node. When the system is in transition, a simultaneous state query to both HAMons might return different results, but the HAMon daemons function such that they quickly converge on a common assessment of the HA state. Figure 81 shows how HAMon communicates within a node and between nodes.
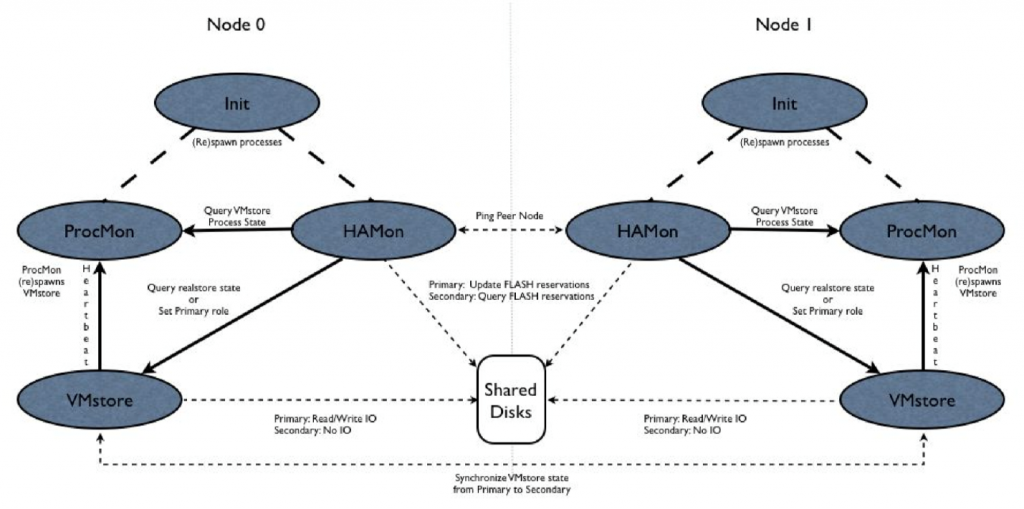
Figure 81. HAMon communications.
Communication between HAMon, ProcMon and VMstore is via thrift. Timeouts are set on the thrift rpcs and a failure to connect or a timeout results in killing the process on the server side of the rpc request. This provides the opportunity for the server process to restart and clear up any transient hang condition. The Init process is responsible for respawning HAMon and ProcMon, while ProcMon restarts the VMstore process.
During normal operation, both nodes will be up and functioning and the HAMon daemons will be exchanging periodic queries for their peer node’s state. If communications fail between the HAMons on the two nodes, the cause (viewed from a single node) is ambiguous. The HAMon on the peer node may have crashed, the network connection between the nodes may have failed, or the peer node may have crashed. The ambiguity in this situation is resolved by having the HAMons communicate via shared disks such that the disks are “fenced” (i.e. only one node has read-write access to the disks).