QoS Design Principles and Methodologies
QoS is an end-to-end problem. For application-originated IO, the same level of service needs to be delivered at various levels of the IO stack (guestOS, hypervisor, network, storage).
Typically, storage appliances are unaware of VMs, but Tintri is an exception. Because of Tintri’s tight integration with hypervisor environments like VMware, Hyper-V, etc., the Tintri file system has information about the VMs residing on it. With this VM information, the Tintri file system can distinguish between IOs generated by two different VMs. This forms the basis for providing per-VM storage QoS in the Tintri file system.
QoS and Performance Isolation
The default QoS policies, which provide automatic performance isolation between VMs, is sufficient for the vast majority of applications. Adjusting the QoS settings may be necessary to handle the small minority of cases where tuning is required in order to address specific performance problems or to guarantee Service Level Agreements (SLAs).
A maximum setting specifies the maximum normalized IOPS a VM can achieve, and can be used to implement SLAs or protect other VMs in the system from rogue VMs. The throughput of a VM without a maximum setting is not limited. The effect of reducing maximum normalized IOPS on individual VMs is an increase in the throttle latency experienced by the VM.
You may want to adjust the maximum settings for the following reasons:
- A VM is getting more IOPS than needed. You may want to decrease the maximum limit to provide a lower level of service.
- You are concerned that a specific VM may use up too many resources on the system. You may want to decrease the maximum limit.
- After setting the maximum limit, you find the VM performance to be worse than expected and decide to increase the maximum limit. You can see this by examining the throttle latency on the VM.
A minimum setting specifies the share of performance resources a VM will be allocated when the system is overloaded. The minimum setting offers a path to provide additional performance protection in the presence of competing VMs. Generally speaking, as long as the system-provisioned normalized IOPS (the sum of all provisioned minimum settings, made visible in the Configure QoS dialog box) is less than 100%, each VM will be able to achieve at least its minimum IOPS setting. The minimum setting becomes effective as the system becomes overloaded. If the system is not overloaded, there are enough IOPS for everyone, so a minimum setting has little effect.
In order for a VM to benefit from a minimum setting, it must be generating a sufficient queue depth. (Note that a minimum setting is not a magic bullet for increasing the performance of your VM. If a VM issues little or no IO, then increasing the minimum setting will provide little benefit.)
When the system is 100% utilized, a VM will receive sufficient resources to achieve its target minimum setting. When the system is less than 100% utilized, VMs will be able to receive more than their minimum settings (i.e., leverage some of the free performance reserves). When the system is 100% utilized, a VM with a higher minimum setting will be allocated proportionally more IOPS than a VM with a lower minimum setting.
To ensure that VMs meet their minimum settings, you should not over-allocate minimum IOPS (each Tintri model has a supported normalized IOPS rating which is generally less than the highest IOPS that the system can achieve). This is made visible to the user in the Configure QoS dialog box.
Certain types of normalized IOPS are more expensive to service than other types of IOPS. Writes are more expensive than reads. Small requests are more expensive than large requests. Flash misses are more expensive than flash hits. A VM issuing larger requests can cause average flash latency to increase, in which case it helps in throttling those VMs so that the VMs performing IOs of smaller request size can meet their minimum normalized IOPS.
When the system is 100% utilized, some VMs may not get desired throughput. Common reasons include: high sequential reads or writes due to provisioning, backup or scans, and/or running very high IOPS applications such as databases.
Examine the latency breakdown for the VMs that are not getting the desired throughput and verify there is significant contention latency. If so, increasing the minimum setting should decrease contention latency and increase throughput.
If other VMs running at the same time and contending for resources have high minimum settings, consider reducing the minimum settings for those VMs or setting a maximum on those VMs.
Remember that given two throughput-intensive VMs, when the system is 100% utilized then normalized IOPS will be allocated in proportion to their minimum settings.
Storage QoS on a broader scale can be categorized into two main areas: space sharing and performance sharing. This chapter will focus on two of the most important use-cases of performance sharing.
Performance Isolation
This is a way of isolating one VM’s IO traffic from another VM. This is essential in virtualized environments because multiple VM users can run different kinds of applications, and one VM user should not be affecting the IO performance of the other.
Tintri Storage QoS uses the built-in VM-awareness to implement per-VM performance isolation. QoS scheduler maintains an IO queue per VM, before they are admitted into the file system read/write pipeline. A proportional scheduler is implemented that uses the VM’s IO request-size and per-request overhead to determine the cost of every IO in the system. It also keeps track of the total outstanding IOs in the read/write pipeline, and schedules the VM’s IOs from the queue proportionally into the pipeline for execution.
Performance Protection
This is a way of providing service levels in a virtualized environment where service providers charge the end-user based on a pre-defined performance consumption metric.
Performance service levels on a VM are assigned by setting a minimum and maximum cap on performance metrics, like normalized IOPS or Throughput. Minimum cap on a VM guarantees at least the specified performance service level for a VM, and Maximum cap on a VM guarantees no more than the specified performance service level for a VM. At times, service levels are used to solve the noisy neighbor problem.
Tintri Storage QoS provides performance protection for VMs, using minimum and maximum performance settings on a per-VM basis. As shown in Figure 6, VM #1 is a rogue VM and the user wants to throttle it. In such cases, the user would set maximum IOPS on the VM. In contrast, VM #5 is deemed an important VM. In such cases the user would set minimum IOPS on the VM. normalized IOPS (with IOs normalized at 8KB) is the unit used for minimum and maximum IOPS settings.
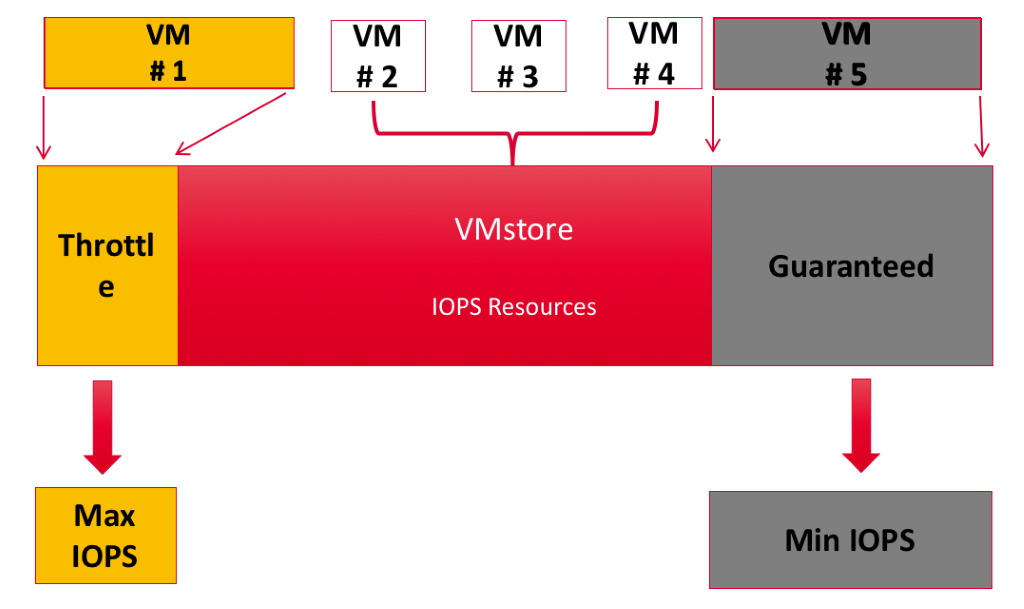
Figure 6. Throttling a rogue virtual machine (VM #1).
Performance protection also gives rise to a set of complexities in which some VMs have service levels set and others do not have any service levels set. This can cause an imbalance between system performance resource allocations, thus causing starvation.
User expectations from guaranteed service levels are heavily dependent upon the amount of system resources available. Every storage appliance has an upper limit on performance it can deliver. Different IO workloads can lead to different performance characteristics. Hence, Storage QoS should be able to inform the user if they have overprovisioned the storage system.
Using the right performance metric is critical in setting per-VM storage QoS policies of minimum and maximum. IOPS, although a widely used metric, does not gauge the performance measures correctly. This is because a VM’s IO request size can differ. Throughput is a more realistic performance gauge. If a user is more comfortable with using IOPS as a metric, then Normalization of IOPS is needed. This calls for a transition from an actual IOPS to normalized IOPS, and storage should provide appropriate visualization, to help understand this normalization.
Storage QoS is complicated, and without the right set of tools to troubleshoot, the desired effect won’t happen, as implementing Storage QoS can directly impact latencies experienced by the VMs. Detailed latency breakdown and its visualization becomes a necessity to troubleshoot problems related to QoS.
In addition to external components, which is the VM’s IO traffic in our case, there are several internal components running on a storage appliance that consume performance resources. Examples include Garbage Collector on a Log Structured file system, Flash Eviction on a Hybrid System, Raid Rebuild, etc. It is essential to isolate performance of these internal components from each other and from the external component. It is essential to give the internal file system components a performance service level, so that they do not get starved themselves or gobble up all the performance resources from user VMs.
Throttling Rogue VMs
Multiple VMs from multiple hypervisors can generate a mix of IO patterns, thus causing the “IO Blender” effect, where a rogue VM can cause a negative impact on the performance of other VMs.
To solve this problem, the storage must throttle the rogue VM so that other VMs do not suffer. If the storage decides to throttle the VM too soon, it will not keep all the system resources busy, thus not achieving the maximum throughput the system is capable of.
If the storage decides to throttle the system too late, it will run into the same problem when the rogue VM eats up the resources, thus making the other VMs suffer. Hence, it is very important for storage to find out the point at which it must start throttling the rogue VM, and provide fairness in the system without leaving any performance resources unused.
For Tintri storage QoS, this point is the maximum performance a given VMstore appliance can deliver for a given kind of workload. However, it is impossible to come up with one number that would fit all the different kinds of workloads.
This is because different IO workloads have different patterns, as a combination of request-size, queue-depth, dedupe, compression, zero-blocks, etc. Also, in hybrid systems some blocks might be cached in SSD for high performance and some cold blocks remain on HDD, thus causing a mix of performance characteristic. That makes it hard to answer the question, “Has the storage subsystem been overprovisioned on performance?”
Tintri has solved this puzzle so that the customer does not need to do any guessing. As shown in the figure below, latency and throughput for a system tend to increase only to a point; the point where the throughput won’t increase but the latency will.
Tintri Storage QoS finds this point of diminishing returns for the current IO workload as a function of request-size, queue-depth, dedupe, compression, and SSD/HDD distribution of the current IOs. After the system has reached the point where throughput will not increase, the QoS scheduler’s enabled, and it will schedule IOs between multiple VMs.
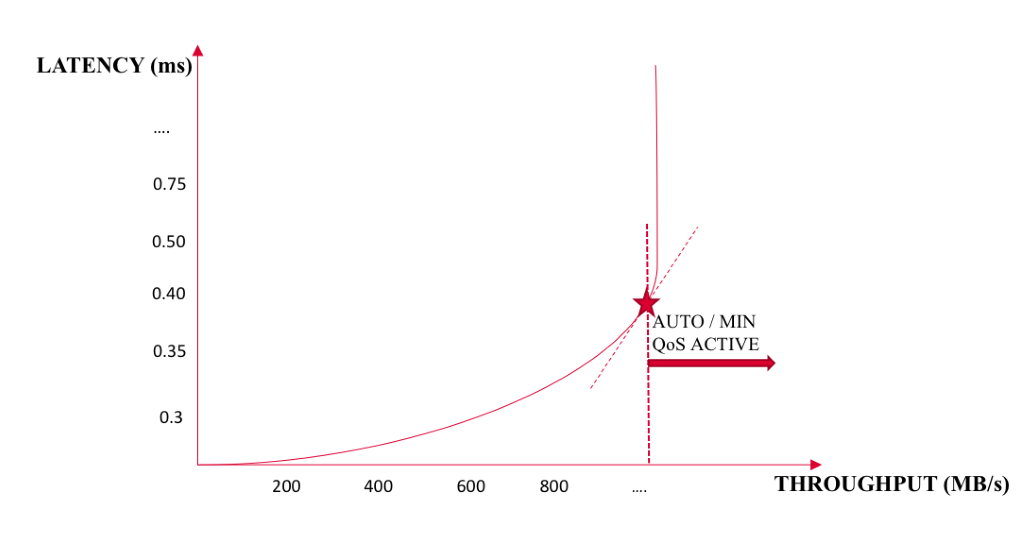
Figure 7. Latency vs. throughput is a key metric for determining storage efficiency.
This behavior of the scheduler is work-conserving as it does not cause any performance degradation, and provides QoS only when the system has been overprovisioned on performance. As discussed earlier, every storage system has an upper limit on the performance it can deliver. If the user drives more IOs than the system can support, the VMs will start contending for performance resources. Any additional latency experienced by the VM when it is contending for resources is called “contention latency.”
Tintri file system computes the system-wide contention latency as the average time IOs spend in the proportional scheduler before they are admitted into the read/write pipeline. As discussed in previous sections, each VM in the proportional scheduler gets a queue. This allows tracking of per-VM contention latency, by measuring the average time IOs from a VM spends in its VM queue, in the proportional scheduler.
The system level contention latency information can be used by the end-user to determine if the system is currently overloaded (Figure 7). To further troubleshoot the performance-overprovisioning problem, the user should be able to determine which VMs are causing most contention in the system. Tintri is able to provide this troubleshooting tool in form of system level and per-VM contention latency. Figure 8 shows a snippet where a VM was experiencing high contention latency due to characteristics of its workload.
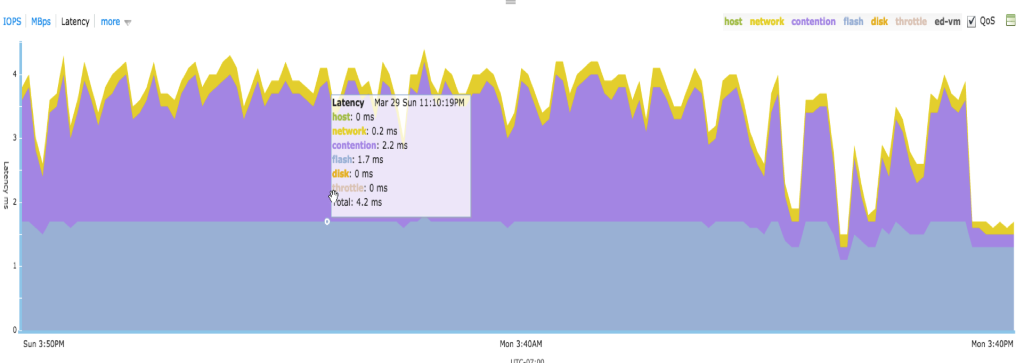
Figure 8. A virtual machine showing high contention latency.
In the majority of cases, fine-tuning QoS settings based on service levels is not needed. However, to handle the small minority of cases where tuning is required, or to provide performance protection with different service levels to different users or applications, Tintri allows users to specify per-VM QoS using minimum and maximum normalized IOPS and to visualize the effect of min/max settings on individual VMs.
We prefer using normalized IOs over the actual IOs measured on a VM, because the former is a more accurate gauge of performance than the latter, as it takes into consideration the request size of IOs.
A normalized IOPS is similar to throughput: IOPS measured at 8KB units. Anything less than a multiple of 8KB is rounded up to 8KB. Examples:
- 4KB => 1 normalized IO
- 8KB => 1 normalized IO
- 12KB => 2 normalized IOs
- 16KB => 2 normalized IOs
The user should not worry about calculating the normalized IOPS on a per-VM basis, as Tintri provides the visualization for the data (see Figure 9). The user should be familiar with the actual IOPS graph, with a read/write split. The graph overlays the normalized IOPS on the top of actual IOPS, so that the user can understand the relationship between actual IOPS and normalized IOPS, in addition to getting familiar with normalized IOPS.
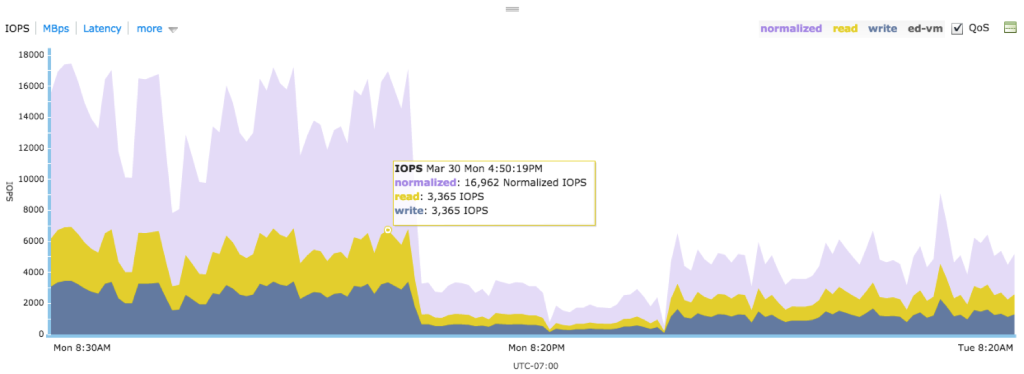
Figure 9. Graphing normalized IOPS.
We leverage the performance isolation infrastructure to implement minimum performance guarantees, for performance protection. The proportional scheduling uses a share assigned to each VM’s queue. For default performance isolation, each VM’s queue has an equal share, thus achieving fair scheduling.
When user increases a minimum performance guarantee (i.e., normalized IOPS) setting on a VM, they identify that VM more important than others. In this case, that VM is assigned a share, which is directly proportional to the minimum normalized IOPS setting on that VM. This allows the system to prioritize this VM over other VMs, and hence achieve defined minimum performance service levels. Users can assign minimum normalized IOPS up to a per-model calibrated number such that they do not cause starvation for other VMs on the system; the performance service level settings are realistic.
If the contention latency on a VM is high and the user thinks that the VM is an important one to their business, a mechanism is provided to reduce that VM’s contention latency.
This can be achieved by increasing minimum IOPS for the VM. Note that Tintri’s storage QoS does not create performance for this VM; it transfers performance resources from a less important VM to a more important VM. This is similar to Law of Conservation of Energy in Physics.
When a maximum normalized IOPS is set on a VM, IOs from that VM may be throttled by the Tintri Storage QoS. If a VM has a maximum normalized IOPS set, IOs from that VM pass through the throttler after they exit the read/write pipeline. This is because IOs have already finished by this time, the exact IO latency for each IO is known. This makes it easy for the throttler to decide if it needs to add latency to the VM’s IO before sending a reply to the client.
The throttler tracks a next service time for every VM and decides if it needs to add an additional latency to a VM’s IO. This additional latency added to VM’s IO is a function of VM’s IO queue-depth, average IO latency on storage without throttling, and max normalized IOPS setting. If an IO is subject to a throttle, it would be added to a throttler queue for the amount of time equal to the throttle latency added for that IO.
Tintri file system computes the per-VM throttle latency by keeping track of the average time the IOs spend in the throttler queues. This latency shows up on VM’s latency chart only when a user sets a maximum setting on the VM and the VM is throttled.
It is hard for the user to predict what latency the VM would experience if they were to set a maximum cap on the VM’s performance. This makes it hard to determine the right number for maximum normalized IOPS. Therefore, Tintri provides a per-VM throttle latency visualization (Figure 10), which helps the user understand the latency impact of setting a maximum normalized IOPS on a VM.
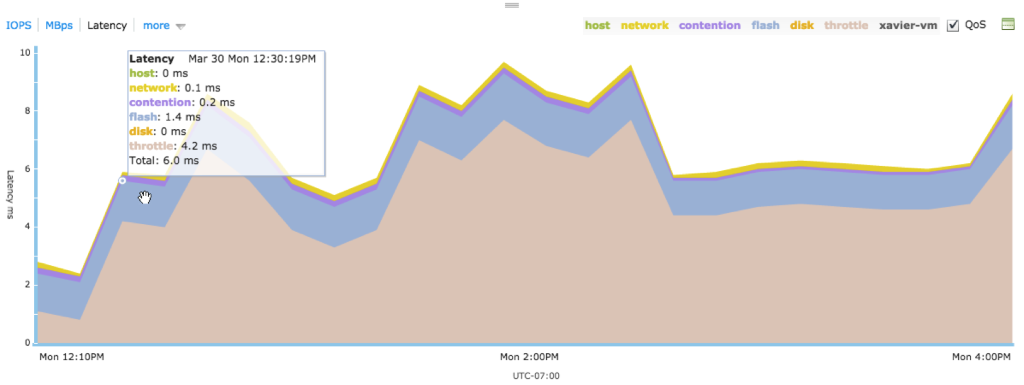
Figure 10. Tintri’s per-VM throttle latency.
So far we have discussed how Tintri solves the per-VM storage QoS problem. In addition to a VMs IO consuming performance resources, any file system can have internal components that can demand their share of performance resources. Tintri file system is no exception, making it important to isolate performance demands for one internal file system subcomponent from other internal file system component or external traffic. Here are some of the common internal file system components that run in background and can consume performance resources:
- GC for log-structured file systems.
- Flash eviction in hybrid file systems, to keep the hot data in flash and evict cold data to disk.
- RAID rebuild, if a SSD or HDD drive fails.
- Read caching in hybrid file system, which involves moves the cold data that has been accessed from HDD into SSDs.
- Per-VM replication for data protection.
Tintri’s Storage QoS considers these internal file system components as internal VMs, and assigns a service level to them. Each of the above components has been calibrated to have a model-specific minimum and maximum.
While configuring per-VM storage QoS, in terms of minimum and maximum normalized IOPS, a user has the flexibility to choose from the following configurations:
- Set both minimum and maximum IOPS for a VM
- Set only minimum and no maximum IOPS for a VM
- Set no minimum and only maximum IOPS for a VM
- Set no minimum and no maximum IOPS for a VM
Tintri provides the flexibility for the user to choose from any of the above. This flexibility results in a heterogeneous QoS configuration, which can be hard to handle. Tintri file system ensures that VMs which do not have any minimum IOPS setting are not starved of resources.
Tintri file system achieves this above goal by carving out system resources into four categories, as shown in the Figure 11.
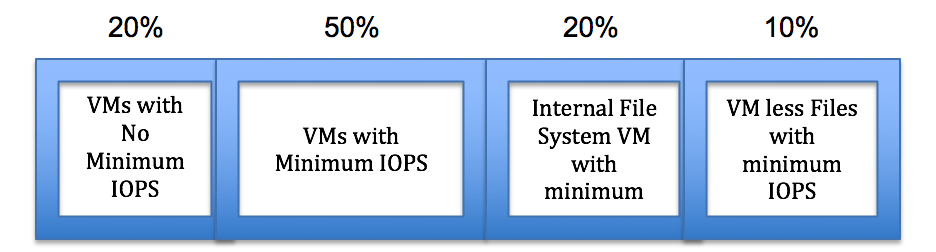
Figure 11. System resource categories.
- VMs with no minimum normalized IOPS set are allocated 20% of system resources. Hence, the default minimum for such VMs can range anywhere from 100 to 1,000, depending upon number of VMs in this category.
- It is recommended to allocate minimum IOPS for VMs from 50% of system resources. This is not a hard limit; just a recommendation.
- All the internal file system VMs are allocated 20% of system resources, so that they get appropriate resources when requested.
- VM less files can also experience IO traffic; the most common reasons are workload provisioning, storage vMotion workload on destination VMstore. This category gets 10% of system resources.
Note: This is not a hard boundary between different categories. VMs in one category can use up performance resources from other categories if they discover that it is available. When there is a lot of contention for resources, each category gets a minimum of what has been allocated to its category.
Thus, Tintri storage QoS understands requirement from different workloads, and isolates them from each other. It also provides an auto allocation of resources when required.
Tintri per-VM storage QoS is native to the Tintri file system and is extremely simple, efficient to use and to troubleshoot because of the following capabilities:
- Leverages the VM-awareness of Tintri Storage Appliance to perform per-VM storage QoS natively. It implements per-VM performance isolation and performance protection. The latter is defined in terms of minimum and maximum normalized IOPS set on a per-VM basis.
- Leverages normalized IOPS as a performance metric to configure per-VM QoS policies, and help with the visualizations of per-VM normalized IOPS in relation to the per-VM actual IOPS.
- Exposes system-level and per-VM contention latency, which helps in troubleshooting storage QoS-related performance problems. It also provides a mechanism to improve performance of a VM with per-VM minimum normalized IOPS configurations.
- Exposes per-VM throttle latency, which aids with per-VM maximum normalized IOPS configuration.
- Provides automatic resource allocation between external VM IO traffic and internal file system workload requirements. It also provides flexible QoS configurations for the end user.