Snapshots and Clones
A popular analogy used to describe a “snapshot” within the realm of information technology is a camera snapshot, which captures an image at the point-in-time when the shutter button is depressed. In our case, the image is not a picture; it is the state of a VM and its constituent files at the moment of the snapshot (Figure 12).
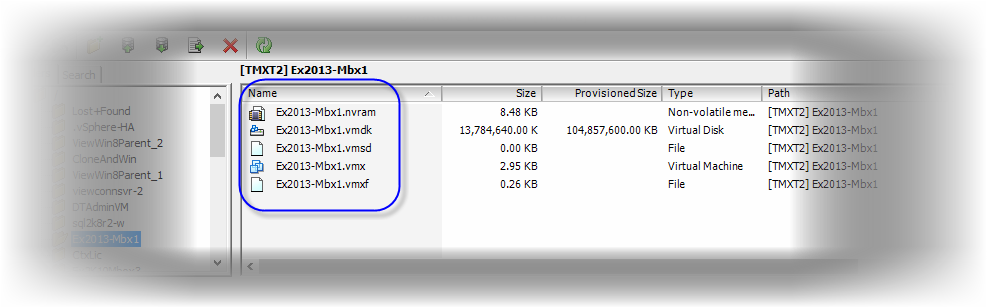
Figure 12. A snapshot of a virtual machine, showing all files.
Creating point-in-time snapshots of VMs provides a versioning of sorts, providing access to a VM and its application data at the exact date and time of a given snapshot (Figure 13).
Snapshots provide a quick way to restore a VM and its application data back to the point-in-time captured by a VM snapshot, and to create new space-efficient VMs, which derive their initial state from a VM snapshot. The rest of this section will detail how snapshots help power server and desktop virtualization, from the deployment of new VMs to fulfilling the data protection and recovery requirements of VMs across data centers.
Figure 13. Snapshots taken at 15-minute intervals.
Data lives within file system blocks. Blocks, when linked together by a file system, constitute files. The bigger the file, the more blocks it will take to store all of a file’s data. The files that make up a vSphere VM, such as one or more virtual hard disk files (.vmdk), as well as its configuration files (.vmx) and other files, collectively comprise what we know as an (individual) VM.
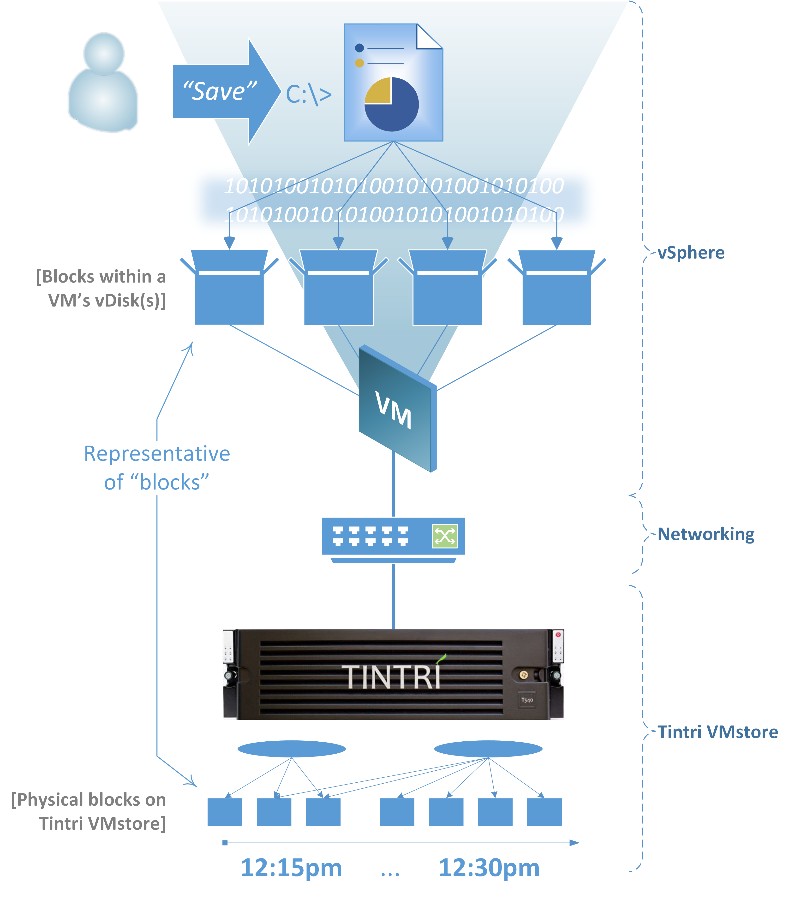
Figure 14. Anatomy of a virtual machine file.
Each block contains data stored within a VM’s files (see Figure 14).
When you save a file, you are instructing an application to save, or persist what you are working on. What actually happens within a VM is that the file’s data is stored in one or more blocks in the VM’s file system. Since we are talking about a virtual machine, the blocks in this case are stored in the VM’s virtual hard disk files, or “vDisks” (e.g. .vmdk files). Those vDisks live on Tintri VMstore. Therefore, when saving changes to a file, the writes are to a VM’s vDisk(s), which exist on Tintri VMstore.
Tintri VMstore keeps track of the changes to all of its VMs’ vDisks within its flash-based file system, and preserves them in snapshots according to an administrator’s operations and configured snapshot schedules.
Consider the following scenario using an assumed VM named “Win8-VM1”
- The first snapshot of Win8-VM1 is created at 12:15pm
- The next snapshot is created fifteen minutes later, at 12:30pm
In Figure 15, note that the snapshots named “Snap-1” and “Snap-2” both have pointers to Block2 and Block3.
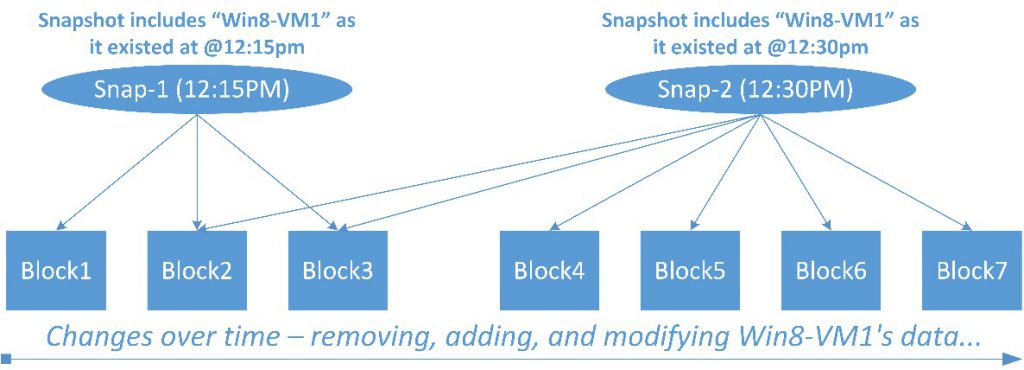
Figure 15. Snapshot creation.
When creating Snap-2, it would be inefficient to make additional copies of Block 2 and Block3 just to include them in Snap-2. Instead, Snap-2, like Snap-1, records pointers to the locations of the existing blocks 2 and 3.
A small example: Imagine that sometime between Snap-1 and Snap-2, at 12:20pm, that you open a spreadsheet, replace a cell value, and then save those changes. The old cell value is in Block1, safely protected by Snap-1. Assume that when you save the spreadsheet, the new cellvalue lands in Block4.
By design, it is not possible to modify a block referenced by snapshots. Block1 is protected by the Tintri file system from overwrites or deletion, as long as any VM or snapshot has a reference to it. Only when a given block’s reference count drops to zero (i.e., no VM or snapshots “point to it”) will Block-1’s location be marked as “free,” allowing new writes to it.
Notice in Figure 4 that Snap-2 does not include a pointer to Block1. This is because writes always occur to new blocks, as opposed to returning to Block1 to modify its data. This technique accelerates IO operations and allows the Tintri file system to quickly record pointers to snapshotted blocks. In addition, the old value (stored in Block1) is not germane to Snap-2. Consequently, Snap-2 does not record a reference to Block1. The prior version of the VM and its spreadsheet as captured at 12:15pm will remain available through Snap-1.
To create a snapshot of a VM, all of its files are collectively snapped at the same point in time, as quickly and as efficiently as possible.
There are two common ways to approach the creation of snapshots for VMs:
- Crash-consistent: Create a snapshot of the VM without taking extra measures to coordinate the snapshot with the VM’s guest operating system and its
- VM-consistent: Create a snapshot while also taking further steps to coordinate the construction of the snapshot with the hypervisor (e.g., vSphere ESX/ESXi), and the guest operating system and its
While both crash-consistent and VM-consistent snapshots can be equally utilized by an administrator, the VM state captured within a crash-consistent snapshot is considered “unknown.” That does not mean it is inaccurate or unusable, just that the VM’s condition was captured on-the-fly.
When a VM is actively performing work, one of its applications may have data in-flight, i.e., not yet written to its vDisk(s), at various points in time. VM-consistent snapshots utilize software within a VM’s guest operating system to synchronize a flush of application data writes from the VM’s memory to its vDisk(s) when creating a VM-consistent snapshot. Consequently, the VM commits any volatile data residing within its memory to its vDisk(s) and, therefore, the VM snapshot. Hence the term “VM-consistent.”
In vSphere environments, VMware Tools installed within each VM’s guest operating system allow the hypervisor to “reach into a VM:” to interact with specific aspects of the VM’s guest operating system, such as the freeze/thaw operations associated with Microsoft Volume Shadow Copy Services (VSS) for Windows. VM-consistent operations with pre-defined scripts are also part of VMware Tools for Linux guest VMs.
There are also other application-specific VSS components for Microsoft Exchange, Microsoft SQL Server, and many others, which provide specialized functionality and extended integration capabilities with various third-party tools. Those components work together with VMware Tools to facilitate backups and data protection, data management operations, etc. While the applications vary, application-specific components play a pivotal role in the VM-consistent snapshots required for advanced database and server VMs.
Storage hardware-accelerated snapshot functionality was available long before virtualization was a mainstream technology.
Hardware-based snapshots were immediately applied to virtualization by storage vendors to help overcome the performance limitations of software-based snapshots. However, while the seemingly universal adaptability of legacy hardware snapshots is significant, so also are the entanglements and limitations of their bonds with their respective storage technologies.
Fundamentally, the design of general-purpose shared storage and SAN systems serves bare metal — or physical — servers and PCs (see Figure 16).
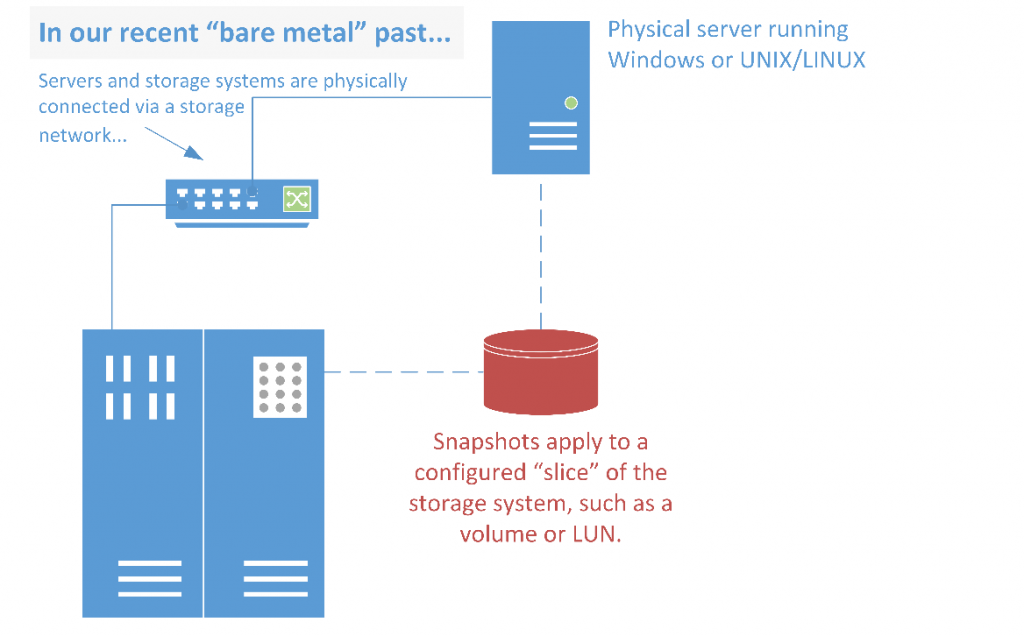
Figure 16. Snapshots with “bare metal” physical servers, before virtualization.
Prior to virtualization, hardware snapshots worked well with physical servers and their applications. Snapshots accelerated the rate at which servers and their application data could be snapped for quick recovery operations.
Hypervisor server software runs on “bare metal:” on the physical server hardware. This paper focuses on vSphere.
With traditionally structured shared storage and modern versions of ESXi, you can provision larger datastores using SAN technologies than ever before due to improvements in VMFS. The tradeoff is that when it comes to hardware-accelerated snapshots using LUNs as datastores, you must create a snapshot of the entire datastore and all of the VMs contained within a given datastore.
There are two choices when provisioning:
- Provision a large number of datastores, one for each VM (via storage system operations) so that you can target individual VMs for snapshots (more specifically, target their containing datastores).
- Place several VMs in fewer datastores to simplify management, sacrificing the ability for “per-VM” snapshot fidelity.
It is a best practice to limit the VMs or vDisks per LUN in SAN environments, due to factors such as per-LUN or target queue depths, protocols, switch fabrics, etc. The impositions associated with these storage-related factors dictates VM and application management. This class of constraints is becoming increasingly outdated.
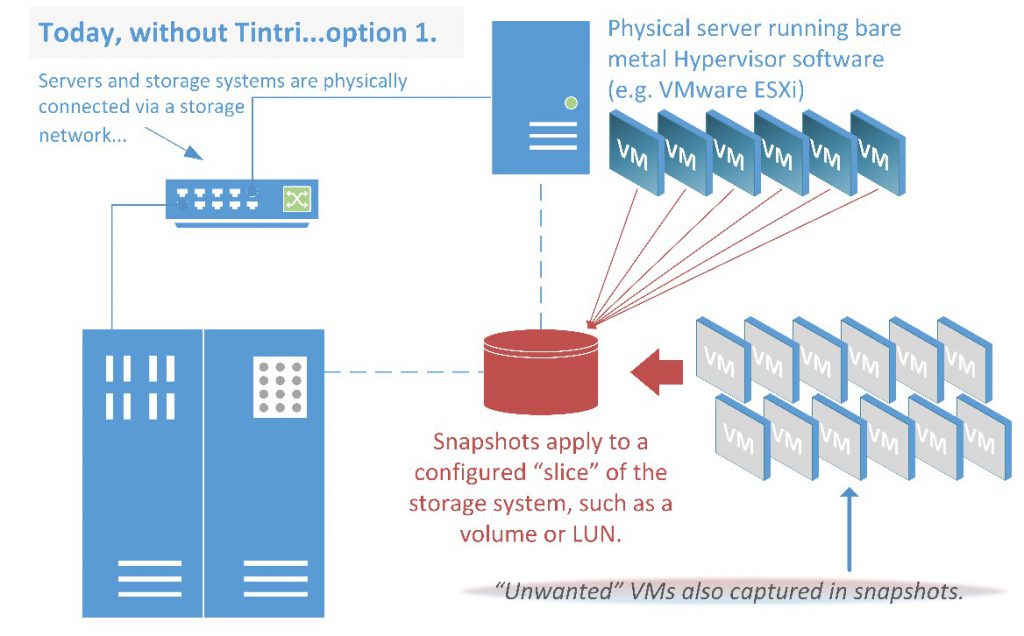
Figure 17. The problems of snapshots at the hardware level.
A snapshot of a LUN or volume captures all of its VMs, irrespective of which VM or VMs are of interest, as shown in Figures 17 and 18. Snapshots are of the LUNs, volumes, or other storage system units, not of the individual VMs. Consequently, complex storage configurations are unavoidable when using traditionally structured, shared storage.
The paradigm shift from bare metal to virtualization has overstretched legacy storage technologies. Newly-marketed flash-based products, which have followed in the footsteps of traditional shared storage designs, embody these same limitations.
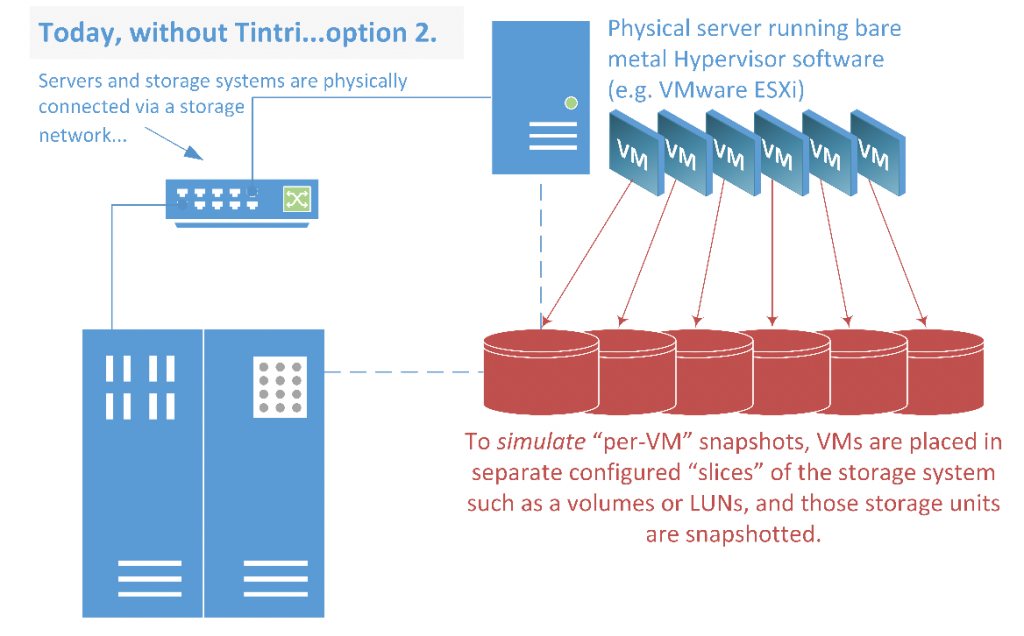
Figure 18. Another way to do snapshots, again showing the limitations of the method.
To meet your criteria for creating snapshots of an individual VM when using traditionally structured storage, you must first configure the storage to match the way you want to manage the VMs. Then, you must forcibly locate the VMs accordingly. The unavoidable rigidity of traditionally structured storage conflicts with the software-defined data center and creates undue pressure on storage and virtualization managers by severely limiting the agility and resource utilization benefits intrinsic to virtualization.
The coupling of snapshot implementations to the internal structures of traditional storage designs creates a circular dependency, in which VM deployments must meet complex, vendor-specific storage placement requirements in order to have their own operational requirements satisfied.
Since these storage architectures do not intrinsically recognize a VM, cannot interact with a VM, and are only capable of creating snapshots of the storage provisions where administrators locate their VMs, they are outdated and poorly adapted to the virtualization experience, forcing virtualization deployments into the bare metal methodologies of the last two decades.
Tintri VMstore has the advantage of being purpose-built from the ground up for flash (SSD) and virtualization by pioneers in storage and virtualization. Each Tintri VMstore is a single datastore with individual, per-VM capabilities woven into its deepest depths and features. This innovative approach leapfrogs traditional storage vendors, which must develop, promote, and support bolt-on software and plugins in an effort to reduce the gaps between virtualization and their storage platforms and snapshots.